第3章 可复算性研究
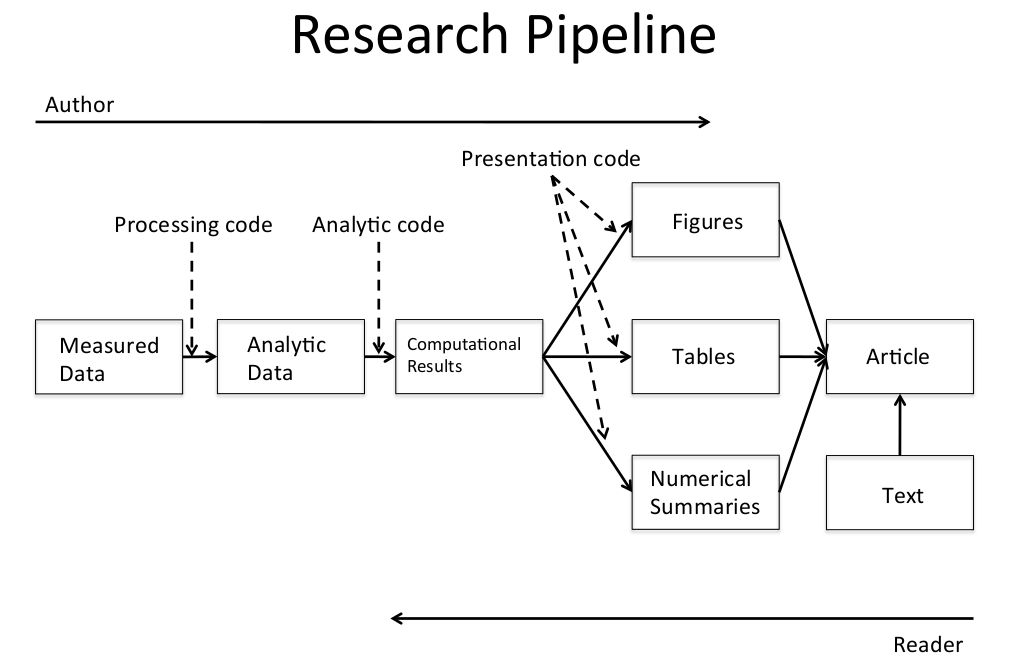
3.4 数据分析步骤
定义问题
- 背后要有科学假设或问题
- 从大到小 具体定义
定义理想数据
- 描述性的 <- 总体数据
- 探索性的 <- 有属性测量的样本数据
- 推断性的 <- 合适的总体 随机采样
- 预测性的 <- 来自同一总体 有训练集与测试集的样本
- 因果性的 <- 随机性研究
- 机械性的 <- 系统中所有组成部分的数据
决定可获取数据
- 网络免费数据
- 购买数据
- 注意使用条款
- 数据不存在 自己创造 <- 实验
获取数据
- 原始数据
- 引用来源
- 网络数据注明数据来源URL与获取时间
整理数据
- 原始数据需要整理
- 如果事先处理过要搞清楚如何处理的
- 了解数据来源
- 需要重新格式化 采样 <- 记录步骤
- 判断数据是否合适 不合适重新获取
探索性数据分析
- 描述性总结数据
- 检查缺失值
- 绘制探索性图
- 尝试探索性分析 例如聚类
统计预测/建模
- 基于探索性分析
- 根据问题确定方法
- 数据转换要解释
- 测定的不确定性要考虑
解释结果
- 描述
- 相关
- 推断
- 预测
质疑结果
- 问题
- 数据源
- 处理过程
- 分析
- 结论
整合写出结果
- 从问题角度出发
- 形成一个故事
- 不要包含分析过程除非用来说明问题 消除质疑
- 以故事而不是时间顺序描述
- 图片要漂亮
写出可重复的R代码
- Rmarkdown文件
3.5 数据分析文件结构
Data
- Raw data 来自网络在Readme里注明url 描述 日期
- Processed data 命名体现处理过程 Readme里注明处理过程
Figures
- Exploratory figures 不必考虑装饰
- Final figures 只考虑装饰
R code
- Raw scripts 不必过分注释 版本控制 不一定用得上
- Final scripts 注释清晰 包括处理细节 只包括文章需要费分析
- R Markdown files (optional)
Text
- Readme files 按步骤记录清晰
- Text of analysis 包括前言 方法 结果 结论 讲故事 有引用
3.6 文本化统计编程-Knitr
- markdown是轻量化结构语言
- R markdown 是轻量化统计结构语言
- 文本+代码块 逻辑清晰
- 文本语言可用latex markdown
- 代码块可用R
- 不用保存输出
- 可缓存结果 cacher包
3.7 结果通讯
研究论文的信息层级
- 题目/作者名单
- 摘要
- 主体/结果
- 支持材料/细节
- 代码/数据
邮件汇报的信息层级
- 题目最好一行一句
- 描述问题 如何实验 总结发现
- 简明扼要
- 如果有问题 写成yes/no形式
- 附件齐全严谨
3.8 检查列表
- 数据选取得当
- 问题简单专一
- 队友靠谱
- 兴趣驱动
- 不要手动处理数据 全部交给计算机
- 少用交互界面 用命令行界面并记录历史
- 使用版本控制 处理降速而冷静
- 记录软件操作环境
sessionInfo() - 不保存结果保证数据可重复
- 使用随机数要说明种子
- 原始数据-处理数据-分析-报告
- 考虑从哪一步开始数据重复性变差